Friday is DataDay. Heute gehen wir mal den folgenden Fragen nach: Wie funktioniert Machine Learning? Wie werden aus Daten intelligente Programme? Wie können Mediendaten (z.B. Bilder) genutzt werden? Was hat Machine Learning mit Training zu tun?
Wie funktioniert Machine Learning?
Vereinfacht gesagt sind Machine Learning Modelle Software-Nachahmungen der übergebenen Daten und der Versuch, Daten durch eine Linie zu teilen (Klassifikation wie „Katze“ oder „Waschbär“) oder Linien durch die Daten zu legen (Regression wie Abschätzen des Autowerts). Oder der Versuch, Muster zu erkennen und diese Muster zwischen „zu allgemein“ und „zu genau“ zu beschreiben.
Es gibt unterschiedliche Modelltypen, die jeweils Vor- und Nachteile haben. Im Grunde arbeiten aber die meisten Typen mit Mechanismen, die wir aus der Geometrie (Geraden, Kurven) oder der Algebra (Vektoren, Matrizen) kennen.
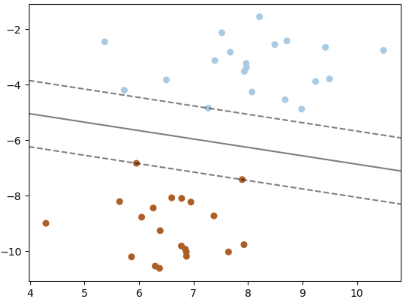
Das Positive vorab: diese Mathematik muss man nicht beherrschen, um ein Modell zu trainieren. Ein Grundverständnis hilft aber sehr, um den richtigen Modelltyp zu wählen.
Wie werden aus Daten ein Modell?
Im Grunde wenden wir einen sehr ähnlichen Prozess immer wieder an.
- den gegebenen Datensatz sichten und verstehen
- Fehlerhafte Daten bereinigen
- Daten anreichern („Feature Engineering“)
- Die Daten splitten (Train, Test, Evaluierung)
- Das Modell auswählen und erstellen
- Das Modell trainieren und testen
- Trainierte Modell evaluieren
- Last but not least: Modell anwenden
Gerade die letzten 4 Punkte klingen zwar sehr umfangreich, bestehen in aller Regel aber nur aus 4 Zeilen Code.

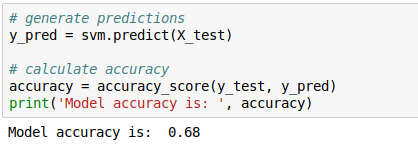
Was bedeutet nun dieses Trainieren?
Solch ein Machine Learning-Modell hat zu Beginn überhaupt keine Ahnung. Man gibt ihm also Werte zur Entscheidung (bspw. Modell, Fabrikat, Kilometerstand, Anzahl der Unfälle, Antriebsart, etc.) und lässt das Modell schätzen und vergleicht es mit dem tatsächlichen Wert für dieses Auto. Je nachdem wie weit die Schätzung entfernt ist, werden Faktoren im Modell angepasst, z.B. weil der Kilometerstand wichtiger ist als die Anzahl der installierten Gurte. Dieser Dreisatz Schätzen-Vergleichen-Anpassen wird tausende Male durchgeführt, was man Training nennt.
Nach jeder Trainingsepoche (z.B. 500 Schätzungen) wird die Genauigkeitsmessung des Models mit Datensätze durchgeführt, die bewusst nicht im Trainingsdatensatz enthalten sind. Man könnte ja dem Modell unterstellen, es kenne ja bereits die Wahrheit…
Ist der Datensatz groß genug, kann man auch noch einen Evaluierungssatz nehmen.
Wie werden Mediendaten trainierbar?
Da unsere Modelle intern mit Geometrie und mit Algebra arbeiten, können sie (Stand 2019) nur mit Zahlen rechnen. Darum müssen alle Objekte, die abgeschätzt, klassifiziert oder vorhergesagt werden sollen, in numerische Werte umgewandelt werden.
Bilder bspw. werden aufgeklappt (statt Pixel in Zeilen und Spalten werden alle Zeilen hintereinander geschrieben) und der Farbwert erfasst. Data Scientists wandeln Bilder gerne von bunt nach graustufig um. Jeder Ton bekommt einen Wert zwischen 0 (schwarz) und 255 (weiß). Warum Graustufen? Es reduziert die Komplexität erheblich ohne großartig Informationen zu verlieren. Ein buntes Bild wird zudem aus 3 Farbräumen erzeugt (Rot, Grün und Blau), bei Graustufen aber nur aus einem Farbraum (schwarz-weiß).
Ähnlich funktioniert es mit Ton, indem bzw. das Tondokument abgetastet wird und dann die Frequenzen ermittelt werden.
Bei gesprochener Sprache wird bspw. mit Speech-to-Text aus Sprache Text gemacht, der weiterverarbeitet werden kann.
Text selbst wird auch durch Zahlen repräsentiert, indem jedes Wort eine eindeutige Nummer bekommt. In einfachen Modellen wird dabei komplett auf die Reihenfolge der Wörter verzichtet (mit dennoch beachtlichen Ergebnissen).
Obwohl sich all diese ganzen Umwandlungen sehr kompliziert und komplex anhören, sind sie es aber gar nicht in der Anwendung. Fertige Werkzeuge übernehmen diese Arbeit. Wieder gilt: das Grundverständnis hilft, die richtigen Werkzeuge auszuwählen.
Wie wird aus dem Modell ein Programm?
Im besten Fall ist das Modell in der gleichen Sprache wie das Zielsystem programmiert. Dann ist eine Direktintegration möglich. Aber auch wenn sich die Programmiersprache oder sogar der Server unterscheiden, ist das kein Problem. So kann man ein Python-Modell in einen kleinen Webserver packen und über eine API abgefragt werden.
Wie groß sollte ein Datensatz sein?
Allgemein kann man dazu keine Aussage treffen, es hängt ein Stück weit auch von den Anzahl der Faktoren und den Faktorwerten oder vom gewählten Modelltyp ab. Man kann aber sagen, dass 50 Datensätze für ein Training viel zu wenig sind. Gute Werte zum Beginn sind etwa 500-1000 Datensätze, damit man abschätzen kann, ob das Modell eine gute Vorhersage tätigen kann.
